Opened on 04/07/2019 at 11:16:19 AM
Closed on 04/13/2019 at 12:48:57 PM
Last modified on 07/29/2019 at 12:44:39 PM
#7444 closed change (fixed)
Compile patterns for simple filters
| Reported by: | mjethani | Assignee: | mjethani |
|---|---|---|---|
| Priority: | P2 | Milestone: | |
| Module: | Core | Keywords: | |
| Cc: | sebastian, kzar, hfiguiere, jsonesen | Blocked By: | |
| Blocking: | #7000 | Platform: | Unknown / Cross platform |
| Ready: | yes | Confidential: | no |
| Tester: | Ross | Verified working: | yes |
| Review URL(s): |
https://gitlab.com/eyeo/adblockplus/adblockpluscore/merge_requests/49 |
||
Description (last modified by mjethani)
Background
A "simple" URL request filter is like the following:
ads ||example.com^ad-tech /\bad[0-9]\.png$/
What defines such a filter is that it has no content type, no domain/sitekey, and no third-party flag, and is simply just a URL pattern, either using the Adblock Plus pattern syntax or a regular expression.
For such filters, we iterate over the filters for each keyword in the request URL and check if the URL matches the pattern in the filter using matchesLocation() (#6994). Instead of this, if we combine all simple filters for a keyword into a single regular expression, it performs much better.
For example, EasyList has the following patterns that are assigned to the keyword web:
-web-ad- -Web-Ad. -Web-Ads. -web-advert- /ads/web/* /web-ad_ /web-ads. /web-ads/* /web/ads/* /web_ads/* =web&ads= _web-advert. _Web_ad. _web_ad_ ||web-jp.ad-v.jp^
Instead of using 14 individual regular expressions or doing string-based matching (#7052) 14 times, it is far more efficient to compile the above into a single regular expression and then match the request URL against this regular expression:
/\-web\-ad\-|\-web\-ad\.|\-web\-ads\.|\-web\-advert\-|\/ads\/web\/|\/web\-ad_|\/web\-ads\.|\/web\-ads\/|\/web\/ads\/|\/web_ads\/|\=web\&ads\=|_web\-advert\.|_web_ad\.|_web_ad_|^[\w\-]+:\/+(?!\/)(?:[^\/]+\.)?web\-jp\.ad\-v\.jp(?:[\x00-\x24\x26-\x2C\x2F\x3A-\x40\x5B-\x5E\x60\x7B-\x7F]|$)/
Since we still need to know which of the patterns matched the request URL, we can use this as a pre-check only. i.e. if the check passes, then we proceed to normal filter matching, but if it fails then there's no need to proceed. This is overall more beneficial since most request URLs would fail this check.
Limitations
There must be some limit to the size of a regular expression on V8 and SpiderMonkey, not to mention other platforms on which this code must run. As a test, here's a simple web page:
<!DOCTYPE html>
<html>
<body>
<script>
setTimeout(() =>
{
for (let i = 0; i < 6; i++)
{
let tokens = [];
for (let j = 0; j < 10 ** i; j++)
tokens.push(Math.random().toString(36));
let source = tokens.join("|");
let label = `${10 ** i} tokens, ${source.length} characters`;
console.time("[create] " + label);
let re = new RegExp(source);
console.timeEnd("[create] " + label);
console.time("[match] " + label);
re.test("https://example.com/foo/bar/lambda?foo=1&bar=2&lambda=3");
console.timeEnd("[match] " + label);
}
},
500);
</script>
</body>
</html>
Output on Chrome:
[create] 1 tokens, 12 characters: 0.015869140625ms [match] 1 tokens, 12 characters: 0.0849609375ms [create] 10 tokens, 139 characters: 0.02001953125ms [match] 10 tokens, 139 characters: 0.115966796875ms [create] 100 tokens, 1363 characters: 0.0869140625ms [match] 100 tokens, 1363 characters: 0.39794921875ms [create] 1000 tokens, 13765 characters: 0.478759765625ms [match] 1000 tokens, 13765 characters: 3.31591796875ms [create] 10000 tokens, 137482 characters: 4.333984375ms [match] 10000 tokens, 137482 characters: 56.684814453125ms [create] 100000 tokens, 1374708 characters: 69.003662109375ms [match] 100000 tokens, 1374708 characters: 945.973876953125ms
Output on Firefox:
[create] 1 tokens, 12 characters: 0ms [match] 1 tokens, 12 characters: 1ms [create] 10 tokens, 137 characters: 1ms [match] 10 tokens, 137 characters: 1ms [create] 100 tokens, 1373 characters: 0ms [match] 100 tokens, 1373 characters: 2ms [create] 1000 tokens, 13746 characters: 1ms [match] 1000 tokens, 13746 characters: 4ms [create] 10000 tokens, 137466 characters: 4ms [match] 10000 tokens, 137466 characters: 22ms [create] 100000 tokens, 1374570 characters: 37ms [match] 100000 tokens, 1374570 characters: 217ms
It is safe to say that, for 1,000 tokens and ~13,700 characters in the source of the regular expression, it works alright at least on a 2017 MacBook Pro.
As a precaution, we can limit the number of "tokens" (URL patterns) to 100.
What to change
The idea is described above, but see patch for the specifics.
Performance impact
Since we create only one RegExp object per keyword (where previously we would create one per filter until we did #7052), there is no significant impact on memory usage.
Further:
- We "compile" the patterns for a keyword only when we come across a URL request matching the keyword; for most keywords, this never happens
- Once compiled, the compiled version is cached so on subsequent URL requests matching the keyword we simply use the previously compiled version
In practice this speeds up filter matching for URL request filters by ~20% for both EasyList only and EasyList with Acceptable Ads.
Hints for testers
Unsubscribe from all filter lists first.
Add three filters -web-ad-, -Web-Ad., and -Web-Ads., and see that the URLs https://example.com/foo-web-ad-bar, https://example.com/foo-web-ad.bar, and https://example.com/foo-web-ads.bar are all blocked. Make sure that the URLs https://example.com/foo-web-adx.bar and https://example.com/foo-Web-Adx.bar are not blocked.
Change the third filter to -Web-Ads.$match-case and see that https://example.com/foo-Web-Ads.bar is blocked but https://example.com/foo-web-ads.bar is not blocked.
Use this Node.js command to generate 101 filters:
node -e 'for (let i = 0; i < 101; i++) console.log(`-web-${i}.`)'
Copy and paste the output into the user-defined filters box on the options page, then make sure https://example.com/foo-web-0.bar and https://example.com/foo-web-100.bar are blocked but https://example.com/foo-web-101.bar is not blocked.
Attachments (5)
{kind=link}
{kind=link}
.png.html){kind=link}
.png){kind=link}
.png.html){kind=link}
.png){kind=link}
.png.html){kind=link}
.png){kind=link}
.png.html){kind=link}
.png){kind=link}
Change History (16)
comment:1 Changed on 04/07/2019 at 11:37:06 AM by mjethani
comment:2 Changed on 04/07/2019 at 11:38:03 AM by mjethani
- Ready set
- Status changed from new to reviewing
comment:3 Changed on 04/07/2019 at 12:50:11 PM by mjethani
Changed on 04/07/2019 at 12:50:41 PM by mjethani
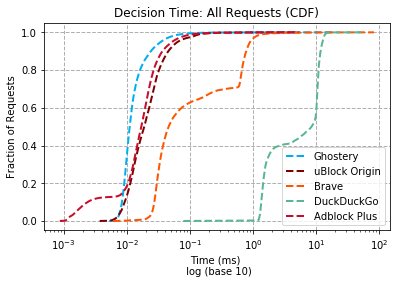
Decision time: All requests
Changed on 04/07/2019 at 12:51:08 PM by mjethani
Decision time: Requests not blocked
Changed on 04/07/2019 at 12:51:22 PM by mjethani
Decision time: Requests blocked
Changed on 04/07/2019 at 12:51:39 PM by mjethani
Memory usage at startup
Changed on 04/07/2019 at 12:51:57 PM by mjethani
Memory usage after matching
comment:4 Changed on 04/07/2019 at 12:56:01 PM by mjethani
- Cc sebastian kzar hfiguiere jsonesen added
comment:6 Changed on 04/07/2019 at 06:52:45 PM by mjethani
- Owner set to mjethani
comment:7 Changed on 04/13/2019 at 11:48:50 AM by abpbot
A commit referencing this issue has landed:
Issue 7444 - Compile patterns for simple filters
comment:8 Changed on 04/13/2019 at 12:48:57 PM by mjethani
- Description modified (diff)
- Resolution set to fixed
- Status changed from reviewing to closed
comment:10 Changed on 04/13/2019 at 12:55:32 PM by mjethani
- Description modified (diff)
comment:11 Changed on 07/29/2019 at 12:44:39 PM by Ross
- Tester changed from Unknown to Ross
- Verified working set
Done. Looks to be working as described.
ABP 0.9.15.2339
Microsoft Edge 44.17763.1.0 / Windows 10 1809
ABP 3.5.2.2340
Chrome 49.0.2623.75 / Windows 10 1809
Chrome 75.0.3770.142 / Windows 10 1809
Opera 36.0.2130.65 / Windows 10 1809
Opera 62.0.3331.72 / Windows 10 1809
Firefox 51.0 / Windows 10 1809
Firefox 68.0 / Windows 10 1809
I tried this with the Cliqz benchmarks.
Adblock Plus before the change:
Adblock Plus after the change:
Comparison with other ad blockers after applying the change (see before here, not including #7435 but including #7296):
Request type _all | | 99% OF REQUESTS | MEDIAN | | ------------- | ---------------------------- | ---------------------------- | | **Ghostery** | **0.072ms** | **0.011ms** | | uBlock Origin | 0.143ms (**2.0x slower**) | 0.019ms (**1.7x slower**) | | Adblock Plus | 0.112ms (**1.6x slower**) | 0.017ms (**1.5x slower**) | | Brave | 1.423ms (**19.7x slower**) | 0.046ms (**4.1x slower**) | | DuckDuckGo | 13.998ms (**193.5x slower**) | 8.498ms (**765.9x slower**) | Request type not_blocked | | 99% OF REQUESTS | MEDIAN | | ------------- | ---------------------------- | ---------------------------- | | **Ghostery** | **0.071ms** | **0.011ms** | | uBlock Origin | 0.127ms (**1.8x slower**) | 0.019ms (**1.8x slower**) | | Adblock Plus | 0.108ms (**1.5x slower**) | 0.017ms (**1.6x slower**) | | Brave | 1.385ms (**19.4x slower**) | 0.041ms (**3.8x slower**) | | DuckDuckGo | 13.724ms (**192.5x slower**) | 2.927ms (**271.0x slower**) | Request type blocked | | 99% OF REQUESTS | MEDIAN | | ------------- | ---------------------------- | ---------------------------- | | **Ghostery** | **0.074ms** | **0.012ms** | | uBlock Origin | 0.215ms (**2.9x slower**) | 0.018ms (**1.5x slower**) | | Adblock Plus | 0.124ms (**1.7x slower**) | 0.016ms (**1.3x slower**) | | Brave | 1.814ms (**24.5x slower**) | 0.083ms (**6.7x slower**) | | DuckDuckGo | 14.956ms (**202.4x slower**) | 8.804ms (**708.5x slower**) |